The useful question about AI in translation is which content to route to it, and which to keep human-led. Machine translation and large language models now handle a large share of business translation well, and they handle some content badly, so the decision is one of routing rather than of whether to adopt them at all.
Machine translation is already the production baseline. Post-edited machine translation rose from 26% of work in 2022 to nearly 46% in 2024, and 62.6% of language service providers now run more than 30% of projects that way (Nimdzi, 2025).
This article gives you a way to make the call: what the terms actually mean, where a neural engine beats a general model like ChatGPT, how to route content by risk, how machine translation fails and how to catch it, and where a human still has to sit. It draws on the experience of our own teams who run this daily.
TL;DR
|
Machine translation and AI translation: what the terms actually mean
Machine translation is software translating text automatically. AI translation is the broader label now covering both purpose-built neural engines and general large language models. The two overlap, but they are not interchangeable, and the difference changes what you should trust them with.
It helps to know the four families you will hear about:
- Rule-based MT: early systems following hand-coded grammar; stilted output.
- Statistical MT (SMT): probability from large bilingual corpora; better, but clunky on fluency.
- Neural MT (NMT): deep learning that reads the whole sentence; the engine behind modern DeepL and Google Translate.
- Large language models (LLMs): general-purpose models like ChatGPT that can translate among many other tasks.
Most business machine translation today runs on neural engines, with LLMs increasingly used alongside them. Knowing which one sits behind a given output is the first step to trusting it appropriately.
Is ChatGPT machine translation?
Not exactly. ChatGPT is a general-purpose large language model that can translate as one of many tasks, where a dedicated machine translation engine is built only for that job. The distinction matters for consistency, terminology, and which languages each handles well.
Translation technology moved from rule-based systems to statistical models, then to neural machine translation, which reads full-sentence context and reads far more naturally. Large language models are the newest layer: trained on huge, diverse datasets, they handle a wide range of topics and adapt to instructions about tone and style.
That flexibility is genuinely useful for drafting and for context-heavy text. A general model is built for many tasks rather than purpose-built for translation, which is why professional adoption is still cautious: fewer than 14% of professional translators report using ChatGPT for translation tasks. The honest verdict is that ChatGPT is a capable first-draft tool that still needs review before it reaches a reader.
Tobias Wiesner, Managing Director of our German branch, spends his days helping clients work out where AI fits in their content. According to Tobias, the trouble usually starts with an assumption that the tool does the thinking on its own.

| “The biggest misconception is that AI works without putting time, energy, and thought into it.” Tobias Wiesner |
NMT vs LLM: which AI to trust with what
A purpose-built neural engine wins on consistency, terminology control, and stable output. A general LLM wins on context handling, flexible tone, and following detailed instructions. Most production workflows use both, for different jobs.
| Dimension | Neural MT engine | General LLM (e.g. ChatGPT) |
|---|---|---|
| Consistency | stable, repeatable output | can vary for the same input |
| Terminology control | strong with a trained engine or glossary | weak without heavy prompting |
| Context handling | sentence and segment focused | broader document context |
| Tone and style flexibility | limited | adapts to instructions |
| Low-resource languages | depends on training data | often weaker, more hallucination risk |
| Best fit | high-volume, stable content | drafts, flexible or context-heavy text |
The practical upshot: treat “AI translation” as two distinct tools. Send stable, high-volume content to a neural engine with a glossary, and use an LLM where flexibility and context matter and a human will review the result.
When to use machine translation, and when to avoid it
Use machine translation where speed and volume matter more than polish, and avoid raw machine translation where a mistake costs money, safety, compliance, or brand trust.
Where machine translation earns its place
Machine translation is the right call when the goal is comprehension and scale. The strongest cases:
- Internal knowledge and documentation, so a multilingual workforce can read company policies and reports quickly.
- High-volume repetitive content, such as FAQs and product listings, where full human translation would not be economic.
- First-pass comprehension, when a team needs to scan foreign-language research or competitor material.
- Otherwise-untranslated content, where the alternative is leaving it in one language entirely.
Picture a manufacturer giving thousands of factory staff fast access to updated safety policies in their own language. Perfect prose matters less than getting accurate meaning in front of people quickly.
Where raw machine translation is the wrong call
Avoid raw machine translation for customer-facing, regulated, specialised, or creative content. The risks:
- Marketing and brand copy, where tone and persuasion carry commercial weight and call for transcreation rather than translation.
- Legal and contracts, where a single mistranslated clause shifts liability.
- Medical and technical content, where accuracy is a safety matter; this is the domain of medical translation and technical translation.
- Anything persuasive or reputational, such as investor or press communications.
A slogan shows the trap. A machine can produce a grammatically correct target-language version that lands flat, or that says something unintended in-market. The output reads fine, and the damage stays invisible until a native speaker sees it.
In Tobias’s experience, this is also where post-editing reaches its limit: editing a machine draft up to a creative standard can take longer than starting fresh.
| “If the client expects a creative work of art, post-editing will not get you there, because then it is faster to translate from scratch.” Tobias |
How to route your content: a decision table
The practical move is to route content by risk and value, raw MT for low-stakes work, MTPE for important business content, human translation for regulated and brand-critical material, rather than treating every file the same.
| Content type | Route | Quality bar | Why |
|---|---|---|---|
| Internal docs, UGC, gist | raw machine translation | readable, accurate enough to understand | speed and volume, low risk |
| Support, product copy, knowledge base | MTPE (ISO 18587) | accurate, consistent terminology | important but high-volume; a human edits the draft |
| Marketing, campaigns, brand | human / transcreation | on-brand, culturally adapted | persuasion and tone carry commercial risk |
| Legal, medical, technical, regulated | human (ISO 17100) | precise, traceable, compliant | a mistake carries legal or safety cost |
Two standards sit behind that table. ISO 17100 covers human translation with an independent reviser; ISO 18587 covers full human post-editing of machine translation output. At AdHoc Translations, we hold both, so each tier runs under a defined process rather than best effort.
A worked example: routing one company’s content
Here is the table applied to a real-shaped inventory. Take a mid-size fashion retailer running a CMS and a PIM, publishing across several European markets.
| Their content | Volume / cadence | Route | Why |
|---|---|---|---|
| Product listings, spec sheets | high, daily | MTPE | volume and repetition; terminology must stay consistent |
| Customer reviews shown on-site | high, continuous | raw MT | readability and intent are enough; speed matters |
| Help centre and FAQs | medium, regular updates | MTPE | important but repetitive; memory grows over time |
| Seasonal campaign pages, hero copy | low, high-stakes | human / transcreation | persuasion and brand voice carry commercial risk |
| Terms, returns policy, compliance | low, high-stakes | human (ISO 17100) | a mistake carries legal exposure |
Most of the volume goes to MT and MTPE, while human effort concentrates where the risk is. The blended cost per word falls without lowering the bar where it counts. For the pricing side of this, see our article on what professional translation costs.
How machine translation fails, and how to catch it
The dangerous failures are the ones that read fluently, so knowing the specific patterns is how a reviewer catches them before they ship. A fluent first read is not a quality signal.
| Failure mode | What it looks like | Why it happens | How to catch it |
|---|---|---|---|
| Terminology drift | the same term translated three ways across one document | no enforced glossary; LLM variability | a termbase and a consistency check on key terms |
| Confident mistranslation | reads perfectly, means the opposite (a dropped “not”, mg vs mcg) | fluency optimised over accuracy | bilingual review of high-stakes segments |
| Hallucination | content added that is not in the source | the model filling gaps, low-resource pairs | a completeness check against the source |
| Register or tone miss | grammatically right, wrong formality or brand voice | model defaults, no style steer | native in-market review |
| Number, date, unit errors | wrong decimal, currency, or date format | locale handling | targeted QA on figures |
This is why the routing table sends high-stakes content to human review. A post-editor or reviser is there to catch the failures a machine cannot see in its own output, which is work of a different kind from polishing prose.
Why AI readiness depends on how you already work
Whether AI translation works for you depends less on the tool and more on how mature your localisation setup already is. A company with translation memories, agreed terminology, defined processes, and people who own quality can put AI to work quickly. A company without those has to build the foundation first.
Tobias frames the change as one of role rather than knowledge: AI reshapes what the linguist does day to day, shifting them from translating from scratch towards preparing assets, steering terminology, and post-editing.
| “AI changes what linguists do, not what linguists know.” Tobias |
That shift is the part teams underestimate. He finds that good output depends on the work that goes in around the tool.
| “Not everybody understands that you don’t just put content in and get the best out. There is work involved, linguistic work and process management.” Tobias |
He is direct with clients when their setup is not ready, because overpromising helps no one.
| “It doesn’t make sense to sell someone a Lamborghini and then deliver a skateboard.” Tobias |
In practice, a few things need to be in place before AI translation earns its keep. Treat this as a readiness check:
- Language assets. Translation memories and a termbase so the engine reuses approved wording and consistent terms. Where these do not exist yet, existing approved content can be aligned to build them.
- Enough content in the language. AI needs material to learn from; a language with little prior content gives weaker output.
- A known audience and tone. Register differs by market, so the target style has to be defined rather than assumed.
- A realistic quality expectation. Post-editing suits good, functional translation; genuinely creative work is better translated from scratch.
- Language readiness varies. Post-edit effort differs by language: some, such as Danish, need light editing, while others, such as Polish, need much more.
None of this requires a finished setup before starting. Centralising requests, adding the right tools, and building a memory from existing content all move a lower-maturity team forward, and each step makes the next AI step safer.
How to evaluate AI translation quality
Judge AI output on completeness, terminology, fluency, and fit for purpose, and treat automated scores as signals rather than a green light to publish.
A practical first check, before any metric:
- Completeness: nothing skipped or merged; AI sometimes drops or fuses sentences.
- Terminology: approved terms and product names used consistently, supported by good terminology management.
- Fluency and tone: natural for the target audience, reading as a native speaker would write it.
- Cultural fit: idioms, examples, and references that transfer to the market.
Buyers also hear about scoring methods. BLEU measures how closely output matches a reference translation, and TER counts the edits needed to reach a professional standard.
A more useful production metric is Time to Edit, how long a linguist needs to bring a segment up to human quality (Translated, 2026). Newer quality-estimation models go further, pre-sorting segments into light or full post-editing before a human starts (Frontiers in Artificial Intelligence, 2025).
All of these measure similarity or effort. None of them tells you the text is safe to publish, which is why high-stakes content still ends with a person.
The security and data question most guides skip
Before routing content through any AI tool, check where the data goes, because pasting confidential or regulated content into a public model can breach the terms you operate under.
Four checks settle most of it:
- Where content is processed and stored, and whether that location meets your compliance obligations.
- Whether your content trains the model, which can expose unpublished or proprietary material.
- Whether there is an audit trail, so you can show how a translation was produced if asked.
- Who has access, and whether sensitive projects are walled off from general use.
A finance team pasting unpublished results into a consumer chatbot to get a quick translation is the kind of shortcut that creates a real problem. A controlled workflow exists precisely so that speed does not come at the cost of confidentiality.
Fitting AI translation into your existing systems
The value of AI translation shows up when it runs inside your existing CMS or PIM, not as a separate copy-paste step, so content flows in and back out without manual handling.
The copy-paste workflow is where time and quality leak away. Content gets exported, pasted into a tool, pasted back, and reformatted for each language, and every manual step is a chance for version drift and error.
The connected alternative is an integration layer between your systems and your supplier. Our our SmartConnect links a CMS, PIM, or shop system to us so content moves automatically, which removes the export and import steps and the errors that come with them.
Routing also needs governance: who approves, how terminology and memory are maintained, and where review sits. Our our SmartDesk customer portal holds that in one place, with each project’s languages, routing, status, and terminology visible and reported rather than scattered across email.
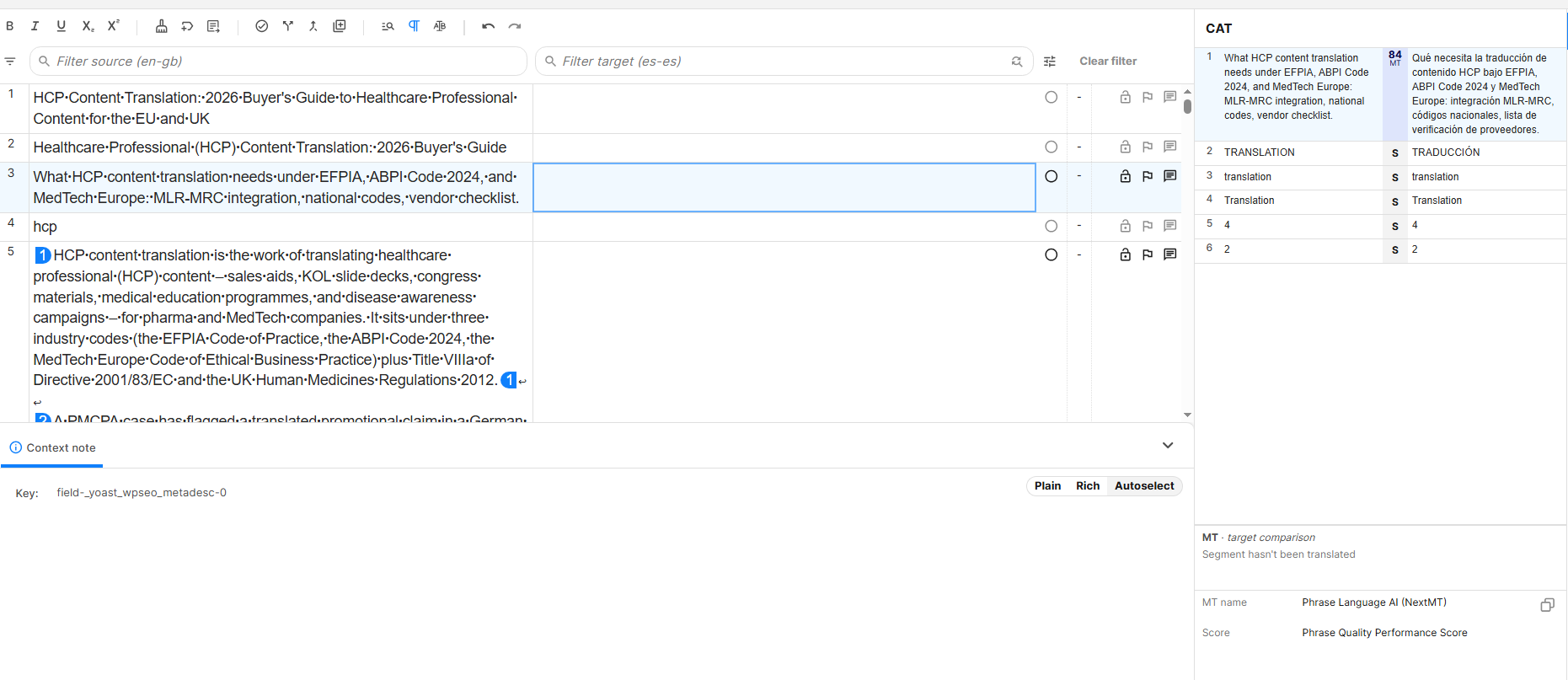
Machine translation inside the CAT editor: an English source segment with its Spanish output and a quality-estimation score of 84. The engine here is Phrase Language AI (NextMT), auto-selected for the language pair. The score signals how much post-editing a reviewer should expect before the text is publishable.
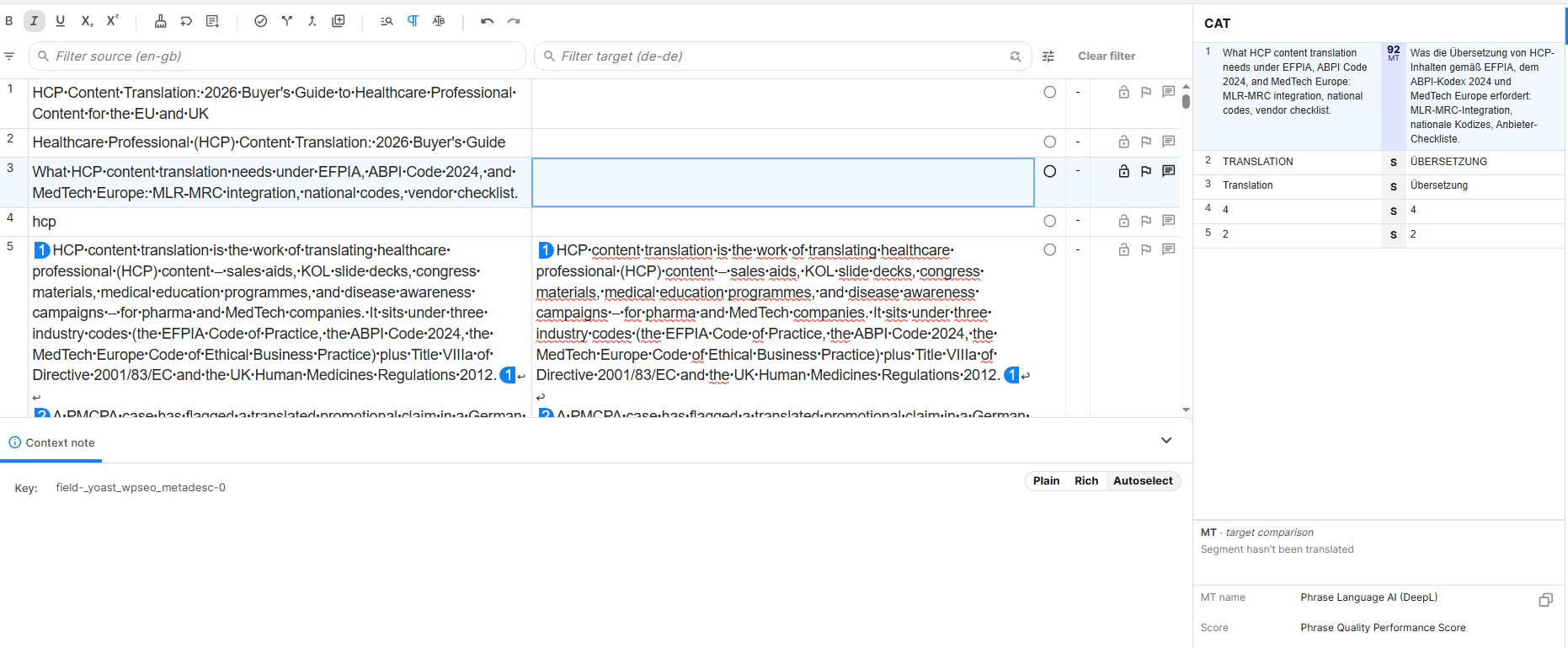
The same source segment into German, scoring 92 with a different engine (Phrase Language AI, DeepL) auto-selected for the pair. A higher score means lighter post-editing, which is why engine choice is made per language rather than once for the whole project.
The same segment into Danish, scoring 69. The lower score shows why post-edit effort varies by language: the same English sentence needs more human work in some target languages than in others, even within one project.
How we approach machine translation and AI at AdHoc Translations
We use machine translation and AI where they fit, paired with human review where quality matters, and we run the whole thing under documented process controls rather than ad hoc.
We have done this since 1990, with 5,500+ linguists working into their native language across 99+ languages, and offices across Northern and Western Europe, India, and the US. We lean on people, process, and technology to keep quality steady as volume grows.
A few things shape how we run AI-supported work:
- we work with multiple engines and Phrase Language AI, and choose the right one per use case rather than betting on a single tool;
- we hold ISO 17100 and ISO 18587, so human translation and post-editing both run under a defined standard; and
- our project teams keep terminology and translation memory consistent across machine and human work, so quality holds across markets
If you would like to map your own content to the right mix of machine, post-edited, and human translation, see how we support your content ecosystem.
Frequently asked questions about machine translation and AI
Is ChatGPT a machine translation tool?
ChatGPT can translate, but it is a general-purpose large language model rather than a dedicated machine translation engine. It produces fluent drafts and adapts to instructions, yet it is weaker on consistency and terminology control than a purpose-built neural engine. For business use, treat it as a first-draft tool that needs review, not a production engine.
What is the difference between machine translation and AI translation?
Machine translation is the function of translating text automatically. AI translation is the broader label that now covers both purpose-built neural engines and general large language models. All AI translation is machine translation, but not all of it behaves the same way, which is why the engine type matters.
When should you not use machine translation?
Avoid raw machine translation for regulated, legal, medical, brand-critical, and creative content, where a mistake carries legal, safety, or reputational cost. These need human translation or, for campaigns, transcreation. Machine translation with post-editing can sometimes work for important but lower-risk content.
Is machine translation the same as a CAT tool?
No. Machine translation generates the translation automatically, while a computer-assisted translation (CAT) tool is the environment a human linguist works in, with translation memory, terminology, and quality checks. A linguist may post-edit machine translation output inside a CAT tool, but the two do different jobs.
Can machine translation handle specialised or technical content?
Sometimes, with post-editing and a trained engine plus an approved glossary, but raw machine translation is risky for high-stakes technical, medical, or legal work. The safe approach is to route specialised content to a subject-matter linguist, or to post-editing under ISO 18587 where the risk allows.
Does using AI translation put my data at risk?
It can, if content goes through a public tool that stores or trains on what you paste in. Before using any AI translation tool, check where the data is processed, whether it trains the model, and whether that meets your compliance obligations. A controlled workflow keeps confidential content out of public models.
Sources
- Nimdzi Insights. The MTPE Efficiency Gap and 2025 survey data on machine translation post-editing adoption. 2025. nimdzi.com.
- Mordor Intelligence. Machine Translation Market size and forecast, 2025–2030. 2025. mordorintelligence.com.
- Translated. Machine Translation in 2026: An Honest Assessment. 2026, for Time to Edit (TTE). translated.com.
- Frontiers in Artificial Intelligence. Quality estimation models for machine translation post-editing. 2025.
- ISO 17100:2015 (Translation services. Requirements for translation services). International Organization for Standardization. iso.org.
- ISO 18587:2017 (Translation services. Post-editing of machine translation output. Requirements). International Organization for Standardization. iso.org.